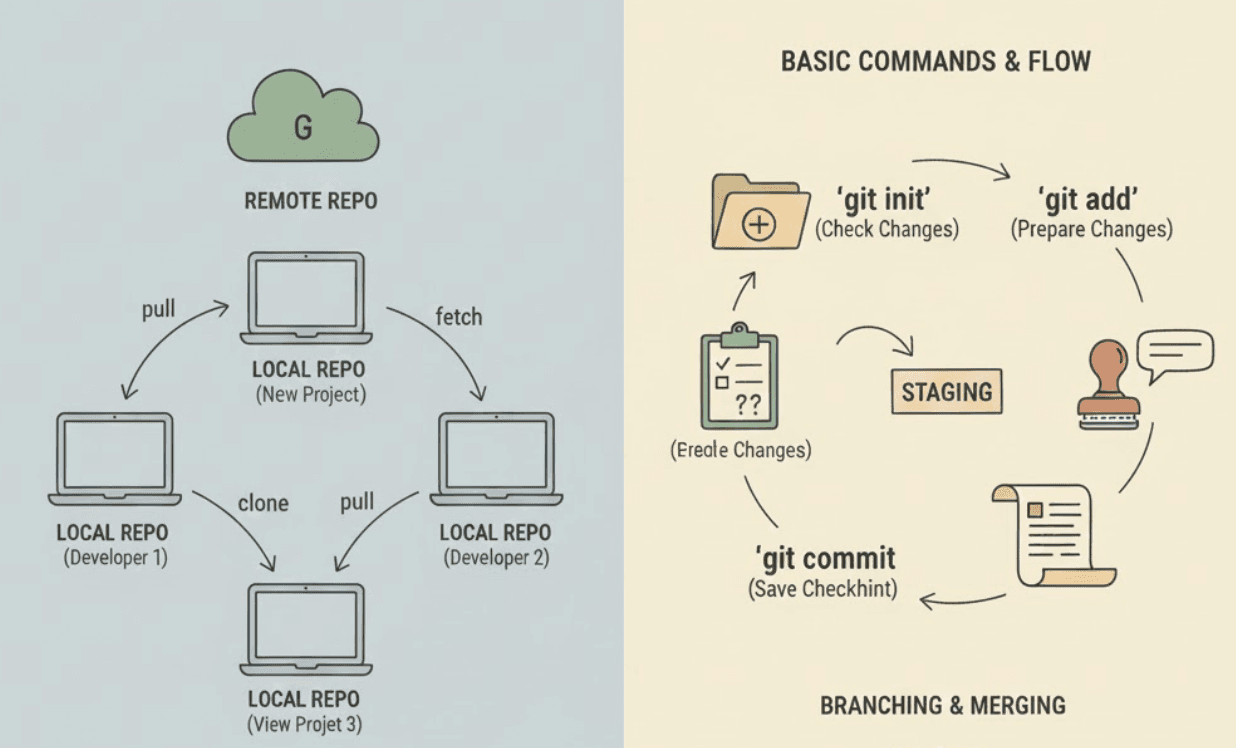
Why Version Control Exists: The Pen-drive Problem
Before the introduction of any version control system, there were developers and there was code.
In this blog we shall discuss, why we needed a version control in the first place and how did developers found a workaround without this.
Understanding the problem
Suppose you have not been introduced to the concept of version control and you have code on your system, now whenever you code you need to make sure the code is perfect and runs without any bug, but in real life scenarios that is something which cannot be achieved. Code that is written will have bugs and would be required to fix, and there would be times when you would need to undo a particular segment or feature for your code to run i.e. get back to the previous version of your software.
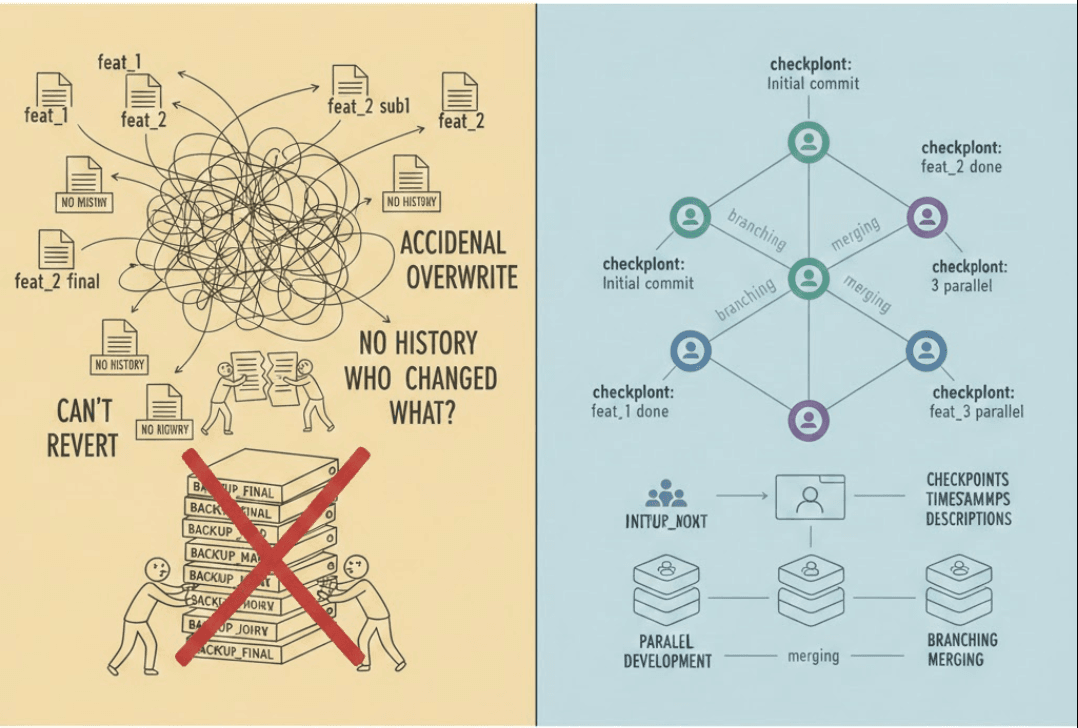
In such a case, the simplest thing would be to create checkpoints. These checkpoints would be such that you write a particular feature of the code and save it as feat_1. Now moving forward when you have a new feature to introduce in your software, you make a copy of feat_1 and keep it as feat_2 and continue to code in it because you never know when you might need to revert back the feature. Even when working on the latest feature, you might need different checkpoints for the sub features, so in such a case what you do is that you would create copies of feat_2 itself, eg: feat_2_sub1.
Now this would work fine when the project is small, you can simply keep all of the code backups in your pen-drive and retrieve them as required, but as the project keeps on growing it would just complicate things out.
There could be scenarios when you are working on two features in parallel, i.e. feat_2 and feat_3 and have two independent copies created from the base code i.e. feat_1. Now when you try to combine both the features it would be a hassle to keep both features and realise what file has changed and what lines are affected.
Another scenario where the pen-drive method is quite ineffective is when you have a group of developers working together on a software, you will need to share the pen-drive which consists all your code to the another developer and what if the other developer does accidental changes in the base code i.e. feat_1 itself? You will have no way to find what changes were done or ways to revert the changes in most scenarios. In such a case, the pen-drive method to store code or distribute with other fellow developers would be a nightmare.
Solution
This problem is already solved by introduction of GIT (a version control system) by Linus Torvalds when he needed something to manage his main project Linux !
A version control system keeps tracks of our changes with proper timestamps and descriptions as to justify why that is a checkpoint. It is really helpful in softwares with huge code bases because it provides features like branching and also allows to work on multiple features in parallel and proper merging of the features. Each saved checkpoint is essentially a version of the software i.e. working state that we can return to later.
This removes the hassle of storing the code as separate files in a storage like pen-drive and keeps a record of your changes in the code base itself. Unlike copying entire folders, Git stores only the changes (diffs) between versions, making it efficient and traceable. And every change that is saved as a checkpoint has a description attached to it which could be others to debug or revert the code at critical times.
A version control system (e.g. GIT) does not prevent bugs or write better code for us — it simply gives us the confidence to experiment, knowing we can always recover.